
Case study
Agent Feedback Component
Designing a building block for improving AI agent performance
Project intro
As AI agents become embedded in everyday workflows, one problem is becoming increasingly clear: there is no standard way to capture feedback on their outputs.
Most systems rely on implicit signals or ad hoc logging, making it difficult to understand where agents fail, how users perceive them, and how to improve them over time.
To explore this gap, I designed and built a lightweight feedback component — a simple thumbs up/down interface that can be embedded directly into AI-powered experiences. While small in scope, this component acts as the entry point to a larger system for evaluating and improving agent performance.
Year
Role
Technology used
Business impact
👎 The problem
AI agents are increasingly responsible for generating content, supporting internal workflows, and making semi-autonomous decisions.
However, organisations lack:
- structured feedback loops
- consistent evaluation signals
- visibility into real-world performance
Without direct user feedback, improving these systems becomes guesswork.
👍 The idea
Create a minimal, embeddable feedback mechanism that captures user sentiment at the point of interaction.
The goal was not just to collect ratings, but to:
- standardise how feedback is captured
- associate feedback with specific agent outputs
- make it programmatically accessible
- lay the groundwork for analytics and optimisation
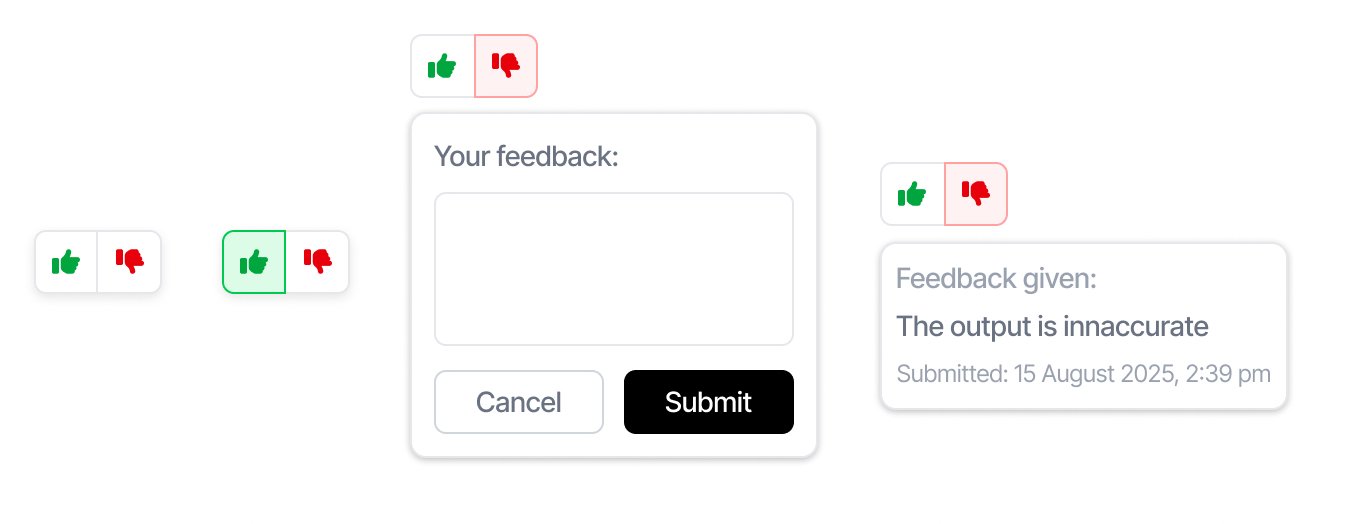
The solution
I built a reusable React component that allows users to quickly rate an AI-generated response.
At its simplest:
- 👍 / 👎 interaction
- optional callback for handling submissions
- lightweight and easy to integrate
<AgentFeedback
context={{ messageId: "msg_123", threadId: "thread_abc" }}
onSubmit={({ payload, context }) => {
// payload: vote, comment, timestamp
// context: your correlation metadata (e.g. messageId)
}}
/>Behind this simple interface is a structured event:
- message ID
- rating (positive / negative)
- timestamp
- optional metadata
This ensures every interaction becomes a usable data point.
Technical approach
- Built as a standalone React package
- Distributed via npm for easy integration
- Uses peer dependencies to avoid bundling React
- Outputs structured events for downstream processing
The component is intentionally lightweight, acting as a frontend interface to a future analytics system.
Interactive demo
Try it
Rate the sample response below. Optional notes open in a small panel—submits fire the same structured event you’d send to your API.
Simulated agent message
Here’s a concise summary of the three options we discussed: Option A minimises risk, Option B ships faster, and Option C balances both. I recommend Option B if we prioritise time to market.
Last callback payload
// Submit or delete feedback to see the event shape here.
Design principles
Five constraints that keep the UI small but position it inside a broader evaluation and improvement system.
Frictionless adoption
The component is designed to be installed and used in minutes, with minimal configuration.
Contextual feedback
Feedback is tied to a specific message or agent output, making it actionable.
Extensibility
The API allows for additional metadata and future expansion (comments, categorisation, etc).
System-first thinking
Although presented as a UI component, it is designed as part of a larger feedback and evaluation pipeline.
Observable events
Structured payloads—message ID, rating, timestamp, metadata—so feedback is legible to analytics and evaluation tools, not only to humans.
Why this matters
A user-first approach
“AI outputs are generated”
“AI outputs are measured and improved”
By embedding feedback directly into user workflows, organisations can:
- identify failure patterns
- measure agent quality over time
- prioritise improvements
- build trust in AI systems

Conclusion
This project started as a simple UI component, but quickly revealed a broader opportunity: AI systems need the equivalent of performance management.
Designing this component was less about buttons, and more about defining:
- what meaningful feedback looks like
- how it should be structured
- how it can drive real improvement
While the current component focuses on feedback collection, it lays the foundation for:
- performance dashboards
- automated evaluation (LLM scoring)
- failure clustering
- prompt and model optimisation
- A/B testing of agent behaviours
In other words, it becomes the first layer in a continuous improvement system for AI agents.
It’s a small UI component with vital strategic impact.
